



Интернет-ресурс может содержать страницы с одинаковым или очень похожим контентом. Они называются дублями, могут заменять в выдаче значимые страницы и препятствовать их индексации. В разделе «Диагностика» Яндекс.Вебмастер начало появляется специальное уведомление.
Почему появляются дубли?
Страницы-дубли появляются разными путями:
- автоматически генерируются «движком» ресурса;
- из-за ошибок веб-мастера – например, если один товар находится в нескольких категориях и имеет разные урлы;
- некорректно настроенные относительные ссылки появляются на несуществующих адресах и выдают контент, аналогичный ценным страницам сайта;
- при изменении структуры сайта, когда существующие страницы привязывают к новым адресам, не удаляя при этом такие же страницы со старыми адресами;
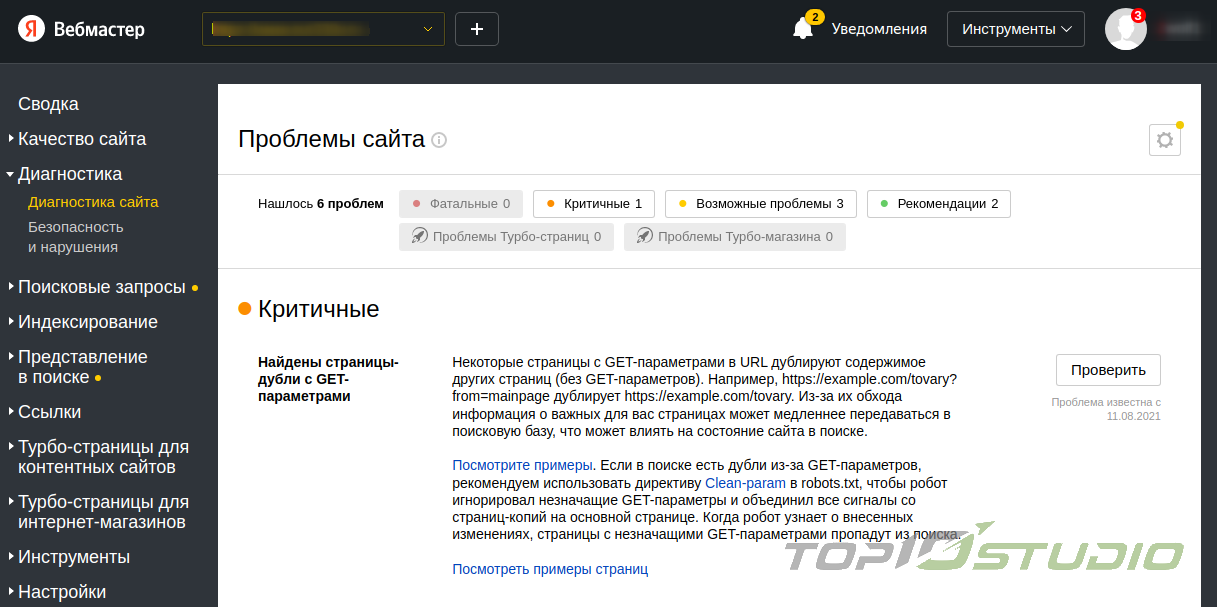
- из-за ссылок с незначащими GET-параметрами.
Страницы с идентичным контентом, но уникальным URL, образуют так называемые полные дубли из-за адресов со слешами или «www» и без них, из-за использования верхнего или нижнего регистра, урлов с HTTP и HTTPS, index.php, index.html, index.htm, default.asp, default.aspx.
Как выявить наличие дублей на сайте?
Чтобы собрать и обработать достаточное количество информации, сервису понадобится время. Поэтому уведомление о дублях на сайте станет доступным спустя пару дней. Подписка для этого не требуется.
Можно обнаружить дубли вручную, для этого переходим в: «Вебмастер» > «Индексирование»> «Страницы в поиске» > «Исключенные» > «Скачать таблицу» (в правом нижнем углу). Выбираем нужный формат и загружаем архив. Страницы со статусом Duplicate являются дублями.

Как оставить нужную страницу?
Чтобы избавиться от «мусорных» страниц, Yandex предлагает следующие способы.
- В файл robots.txt добавить директиву Disallow, которая запретит ботам индексировать ненужные страницы;
- Запретить индексацию за счет мета-тега noindex – в отличие от robots.txt, это прямая команда, которую не будут игнорировать роботы. Метатег запрещает поисковым ботам индексировать страницу, но переходить по размещенным там ссылкам они смогут.
- Настроить HTTP-код ответа 403/404/410, но этот вариант используют редко, поскольку пользователи будут попадать на недоступные адреса, если где-то останутся ссылки страниц, которые перестанут учитываться.
С дублями можно поступить так:
- Для страниц-дублей с незначащими GET-параметрами нужно добавить в файл robots.txt межсекционную директиву Clean-param и перечисление всех возможных GET-параметров через амперсанд. Последних может быть бесконечное множество, поэтому в выдаче нужно выявлять новые и обновлять директиву. Кроме того, перечислить все и вместиться в 500 символов – невозможно. Поэтому такой способ хорош для маленьких сайтов.
- Установить 301 редирект, который автоматически переадресовывает с одной страницы на другую и передает основной странице ссылочную массу с дублирующей страницы. Это основной способ удаления полных дублей.
- Если страницу удалять нельзя или необходимо оставить открытой, можно использовать атрибут rel="canonical", разместив его между тегами Указывая каноническую ссылку, определяют приоритетный для индексации адрес. При этом, если страницы имеют незначительные отличия или часто обновляются, то они могут попасть в индекс.
Устранив дублирующий контент на сайте, нужно выполнить повторную проверку. Так можно оценить эффективность выбранного метода. Анализировать сайт на наличие технических ошибок рекомендуется регулярно, чтобы вовремя устранять их.