



Новый алгоритм Яндекса «Королев» характеризуют как искусственно созданную нейронную сеть, влияющую на ранжирование по «длинным хвостам», обладающую скрытыми слоями, дополнительный индексом и поиском, учитывающим сематический смысл. В такое многим даже трудно поверить. Действительно, все так серьезно? Разбираемся с чудо-алгоритмом.
В конце лета 2017 года Yandex запустил новый выше упомянутый алгоритм, который был официально проанонсирован в блоге поисковика для вебмастеров и в блоге на Хабрахабре. На практике настоящие изменения выдачи отмечались и раньше при анализе апдейтов SERP.
Алгоритм был запущен с для того, чтобы улучшить качество выдачи по низкочастотникам, состоящим из нескольких слов. По таким поисковым фразам качество выдачи оставляло желать лучшего. Особенно это было заметно в сравнении с Гугл. В эту категорию поисковых ключей нередко попадают и голосовые запросы, которые пользователи задаются с мобильных устройств. Рассматриваемый алгоритм имеет отличие от «Палеха». Оно выражается в том, что в общий список добавлены новые факторы ранжирования, которые учитывают:
- Сходство значения, скрытого в поисковым запросе, с содержанием всей страницы, а не только с заголовком статьи и Title.
- Релевантность документа аналогичным по смыслу пользовательским запросам.
- Новое технологическое решение с расчетом определенных факторов в процессе индексирования и введением дополнительного индекса.
Для понимания смысла, который юзер вкладывает в поисковую фразу и того значения, которое раскрывается в публикации, используется нейронная сеть. Она выступает в качестве одного из способов машинного обучения, на котором основывается высчитывание ряда факторов, применяемых в сортировочном алгоритме.
Мы оперируем понятием «смысл» без кавычек, однако важно понимать, что внутреннее содержание, которое определяется посредством машинного алгоритма и тот смысл, который вкладывает в запрос его автор, не могут быть равнозначными понятиями.
Различные виды запросов: как на них влияет «Королев»?
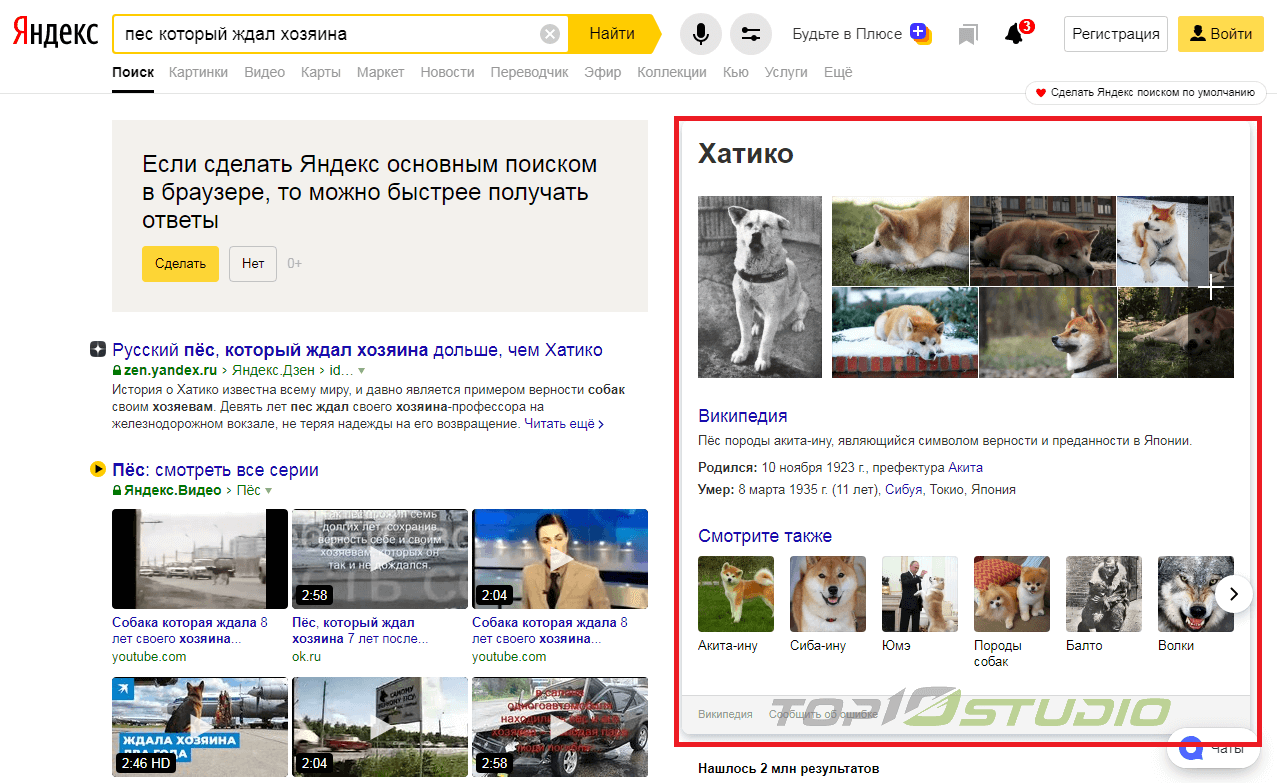
Алгоритм, главным образом, влияет на результаты выдачи по низкочастотникам. Они могут быть редкими или очень длинными, или соответствовать обеим этим характеристикам. Такие ключи часто задаются на языке, который сложился исторически и используется в общении. Например: «видео где заключенный сбегает из камеры после очень долгого срока».
В SEO такие ключи классифицируются как низкочастотные и микронизкочастотные. Как правило, такие ключи являются информационными, но иногда могут встретиться и коммерческие варианты. Например: «цена мороженого которое делают из фруктового сока». Именно такие ключи называются «длинными хвостами» на сеошном жаргоне. Из общего количества ключей на них приходится около 30-35%.
Существует ряд поисковых фраз, для которых новая группа факторов играет важную роль, значимость, но Яндекс не совсем уверен в корректности их использования. Чтобы убедиться в том, что алгоритм работает правильно, проводится анкетирование среди посетителей Яндекса. На странице выдачи можно увидеть вопрос: «На ваш запрос можно дать короткий и однозначный ответ?»
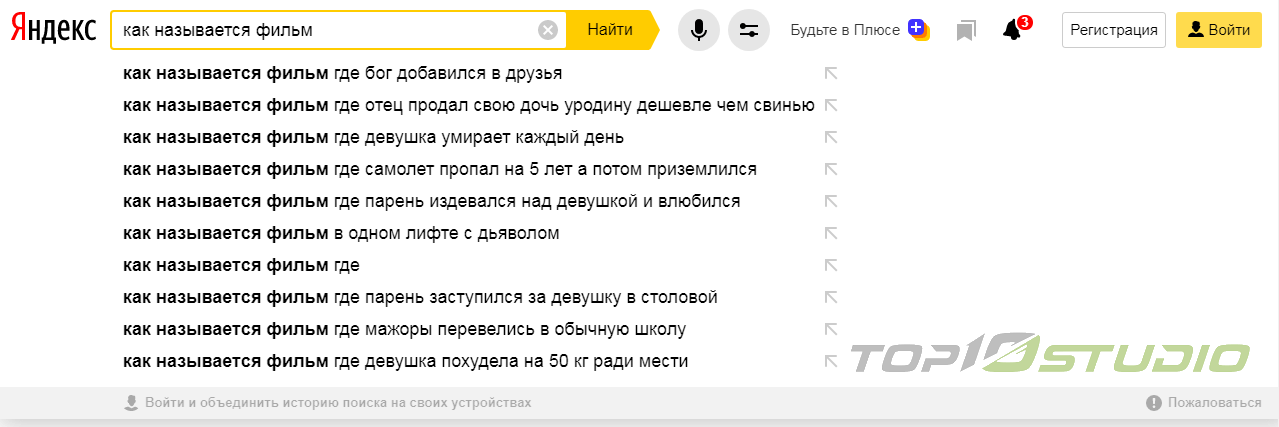
Сравниваем: Яндекс против google
Мы ручками оценили качество выдачи по 100 запросам в режиме «Инкогнито» через несколько дней после официального анонса. В результате исследования SERP обоих поисковиков по набору выбранных нами ключей, мы пришли к следующим заключениям:
- Качество отработки алгоритмов «Королев» и «RankBrain» сопоставимо друг с другом.
- В большинстве случаев выдача по качеству практически не отличается. Это свидетельствует о схожести данных алгоритмов.
- Доля поисковых запросов, для которых алгоритмы с успехом определяют смысл, не превышает 80% из выбранных.
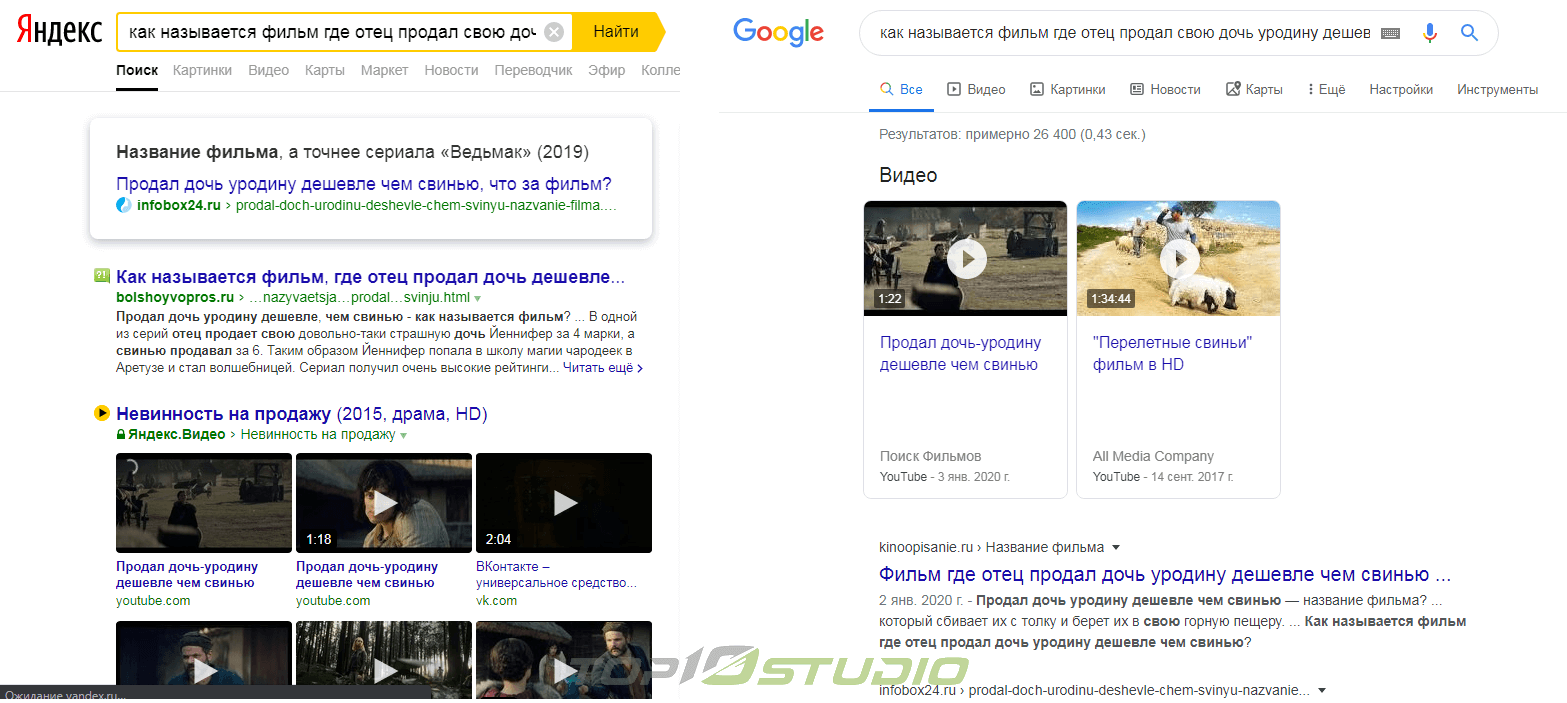
Значение алгоритма для СЕО
Какое влияние «Королев» оказывает на поисковую оптимизацию? Особенно существенные изменения прослеживаются для ключей, по которым отсутствуют страницы с точными вхождениями, то есть, с традиционной точки зрения, не хватает необходимого числа соответствующих ответов.
Это означает, что за счет новой категории факторов, ранжирование по среднечастотным и высокочастотным запросам, по которым продвигается большая часть коммерческих сайтов, почти не изменится.
На практике точное вхождение поисковой фразы, если таковое присутствует, имеет большее значение, чем новые факторы ранжирования алгоритма. Документы с такими вхождениями оказываются выше в поисковой выдаче, нежели страницы с угаданными смыслами фраз из «длинных хвостов».
Таким образом, если SEO-специалист проведет мероприятия, способствующие улучшению «традиционных» факторов ранжирования, то страница займет первые места в поиске по нужному низкочастотному запросу. В этом смысле алгоритм «Королев» не внес ничего революционного в процесс.
В ранжировании по коммерческим запросам группа новых факторов алгоритма «Королев», разумеется, может влиять на изменение позиций в ТОП поисковой выдачи. Чтобы улучшить значения по ней, эффективнее всего использовать технологии LSI-копирайтинга.
Техническое воплощение алгоритма
Чтобы ускорить формирование ответа на пользовательский запрос, в алгоритме используется исключительно финишная формула сортировки. Процесс проходит в несколько стадий, на каждой из которых отбираются кандидаты для следующего, более сложного алгоритма.
Поскольку вычисление смысла является задачей довольно сложной для максимального количества текстов, он не может происходить в несколько секунд. Поэтому с финального этапа ранжирования (как это было реализовано в «Палехе»), он был перемещен на стадию индексирования.
Чтобы ускорить финальный этап ранжирования и освободить вычислительные ресурсы, был разработан и внедрен еще один индекс. Он уже включает в себя предварительно вычисленные сведения о примерной релевантности всех веб-страниц для всех популярных у пользователей высокочастотных ключей, состоящих из одного и двух слов.
Эта мера дала возможность освободить вычислительные мощности для поиска. Без них невозможно отрабатывать сложные модели, которые базируются на нейронных сетях. В данном случае речь идет именно о новом наборе факторов из Королева. Многочисленные оценки асессоров и пользовательские факторы легли в основу обучения нейронной сети. Именно на них оно и опиралось.
Кстати, для того, чтобы увеличить совокупное количество оцененных пар: поисковая фраза-документ, Yandex запустил публичный сервис «Толока». Это позволило во много раз увеличить количество и асессоров, и оценок.
Публично анонсированные примеры не работают, потому что пользовательская модель поведения по ним быстро меняется, а их популярность возрастает.
Прогнозируем будущее
Формула ранжирования выстраивается в поиске Яндексе с использованием машинного обучения, начиная с 2009 года. Окончательная формула и в настоящее время складывается по методике Матрикснет. Но не все факторы в ней простые, так как получены посредством нейронных сетей. В данном случае подразумевается машинное обучение. В определенном смысле это напоминает матрешку.
В будущем предполагается:
- Оптимизировать качество оценки семасиологического соответствия (смысла) ключевой фразы и документа.
- Сделать обработку более полной.
- Изменить логику фильтрации веб-страниц на самой первой стадии.
- Персонифицировать выдачу, то есть учитывать индивидуальные интересы посетителей поисковой системы.
Давайте вмести следить за тем, как события будут развиваться дальше!